
Query Event Hubs Archive with Azure Data Lake Analytics and U-SQL
Wednesday, December 21, 2016
Azure Event Hubs Archive is a feature that allows the automatic archiving of Event Hubs messages into Blob Storage. A simple setting is all it takes to enable archiving for an Event Hub. It couldn't be easier.
Event Hubs Archive writes out the messages into files using Apache Avro serialization, which is a binary format with embedded schemas that is quickly becoming popular.
Azure Data Lake Analytics added an open source Avro extractor this week. In this article, we'll look at how to use Data Lake Analytics to query data stored by Event Hubs Archive.
Enabling Event Hubs Archive
The Archive feature can be turned on for any Standard Event Hub (it is not available on Basic because it needs its own consumer group). To enable it on an existing Event Hub, go to its properties. Turn on Archive, set the time and size windows (these dictate how granular the files are), and select a storage account and container to write the files to.
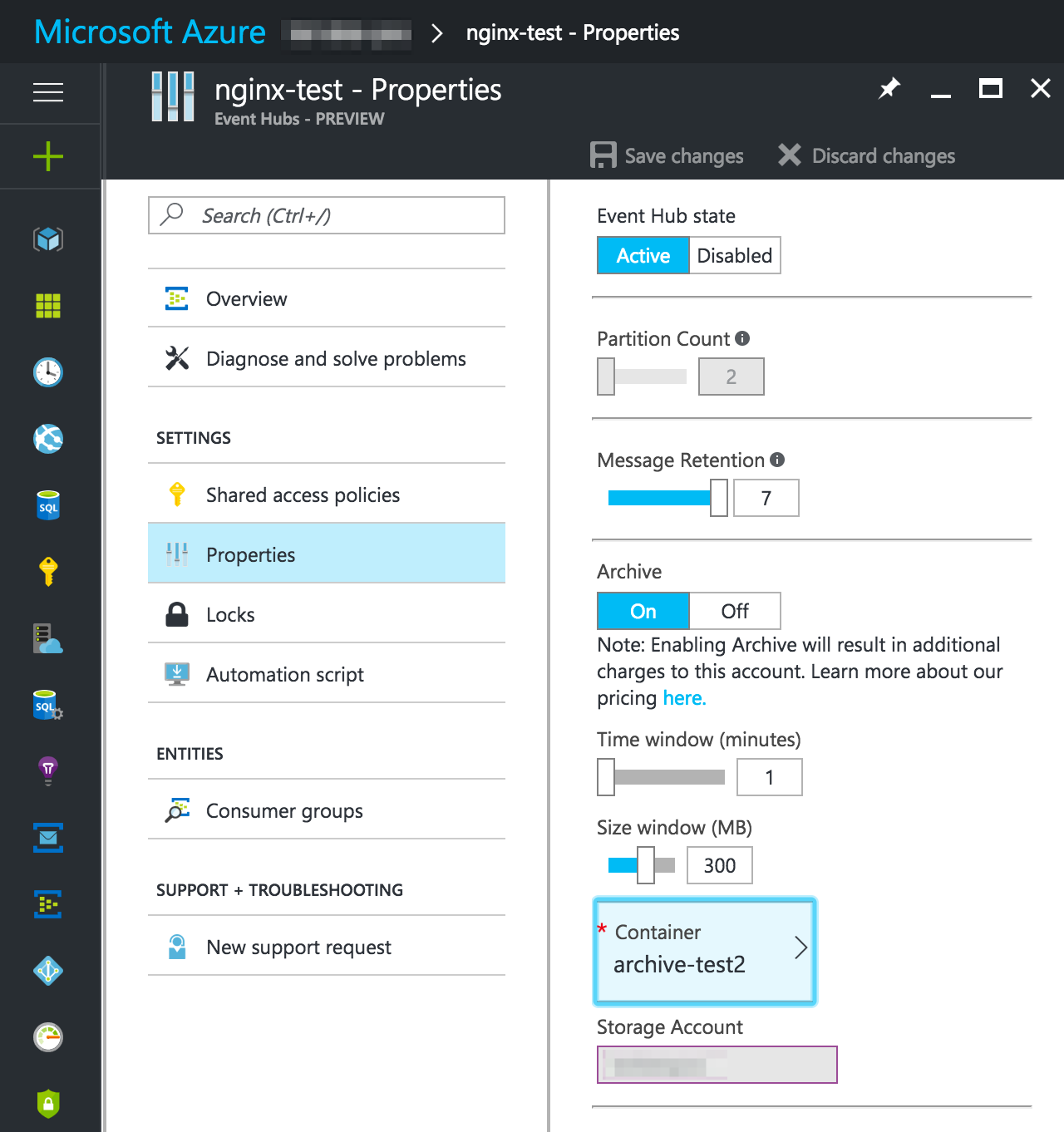
That's it, we're done. Of course, we can also do the same when creating a new Event Hub using the portal or an ARM template.
If there's data flowing through the Event Hub, check the storage account in a few minutes and we should see some files written there. One tool we can use to do this is Azure Storage Explorer.
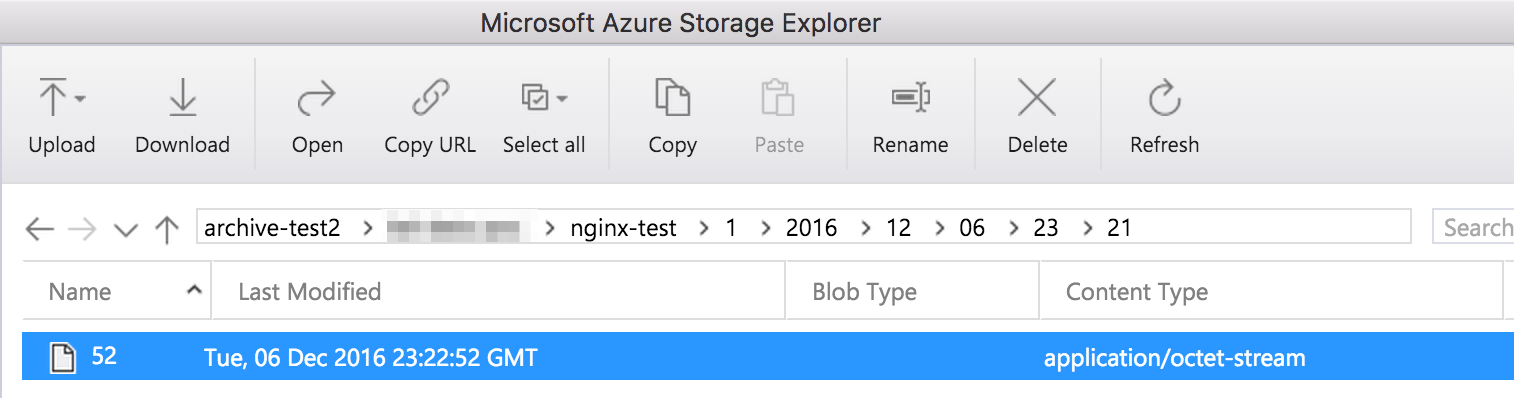
Note the path... after the namespace and Event Hub name, the first number is the Event Hub partition id, followed by the year, month, day, hour, and minute. In the minute "folder", there are one or more files created for messages received during that timeframe. The format of the path will be important when we extract the data later.
Setting up Azure Data Lake Analytics
Data Lake Analytics is Azure's fully-managed, pay-per-use, big data processing service. It can extract data from Data Lake Store (of course), Blob Storage, and even SQL Database and SQL Data Warehouse.
We'll use its ability to extract data from Blob Storage to process the files created by Event Hubs Archive.
Adding a data source
Before we can extract data from Blob Storage, we have to set up a data source in Data Lake Analytics. One way to do this is via the portal.
In the Data Lake Analytics account, select Data Sources and click Add Data Source and fill out the required information.
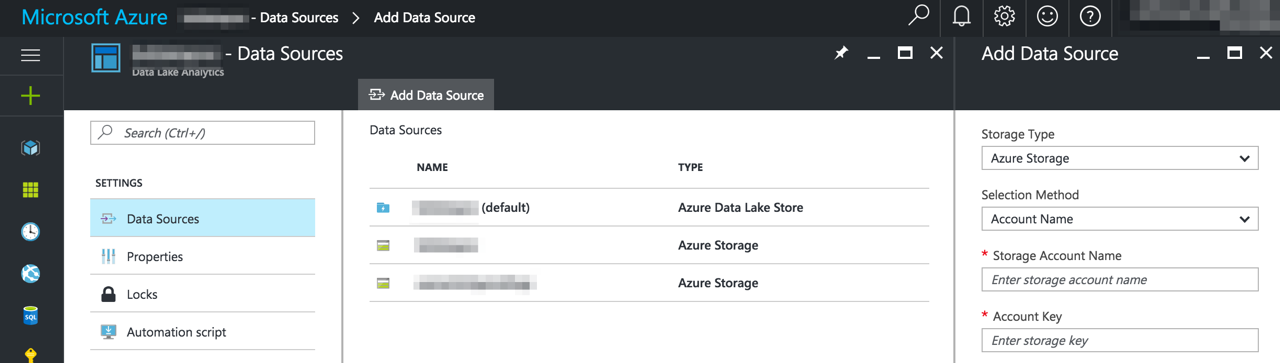
Now the Data Lake Analytics account is set up to connect to the storage account.
Adding the Microsoft.Analytics.Samples.Formats assembly
Azure Data Lake Analytics provides out of the box extractors for TSV, CSV, and other delimited text files. It also allows us to bring our own extractors for other formats. The U-SQL team maintains a repository of extractors that we can add to our Data Lake Analytics accounts. They support JSON and XML; and starting this week, Avro is supported as well.
In order to use the open source extractors, we need to clone the repository and build the Microsoft.Analytics.Samples solution. Then we can use Visual Studio to add these assemblies to the Data Lake Analytics database:
Microsoft.Analytics.Samples.Formats.dllNewtonsoft.Json.dllMicrosoft.Hadoop.Avro.dll
The full instructions are here. It's simple to do and it only has to be done once per Data Lake Analytics database.
Extracting and processing Event Hubs Archive data
Now we're ready to get down to business and write some U-SQL. I like using Visual Studio for this. Using an existing Data Lake Analytics project or a new one, create a new U-SQL file.
In the first few lines, we'll reference the assemblies we deployed above and add some USING statements to simplify the code we're about to write.
REFERENCE ASSEMBLY [Newtonsoft.Json];
REFERENCE ASSEMBLY [Microsoft.Hadoop.Avro];
REFERENCE ASSEMBLY [Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Avro;
USING Microsoft.Analytics.Samples.Formats.Json;
USING System.Text;
Extracting Avro
Next, we'll use the AvroExtractor to extract the data.
@eventHubArchiveRecords =
EXTRACT Body byte[],
date DateTime
FROM @"wasb://mycontainername@mystorageaccount.blob.core.windows.net/my-namespace/my-event-hub/{*}/{date:yyyy}/{date:MM}/{date:dd}/{date:HH}/{date:mm}/{*}"
USING new AvroExtractor(@"
{
""type"":""record"",
""name"":""EventData"",
""namespace"":""Microsoft.ServiceBus.Messaging"",
""fields"":[
{""name"":""SequenceNumber"",""type"":""long""},
{""name"":""Offset"",""type"":""string""},
{""name"":""EnqueuedTimeUtc"",""type"":""string""},
{""name"":""SystemProperties"",""type"":{""type"":""map"",""values"":[""long"",""double"",""string"",""bytes""]}},
{""name"":""Properties"",""type"":{""type"":""map"",""values"":[""long"",""double"",""string"",""bytes""]}},
{""name"":""Body"",""type"":[""null"",""bytes""]}
]
}
");
There's quite a bit to unpack here. Let's start with the URI.
wasb://mycontainername@mystorageaccount.blob.core.windows.net/my-namespace/my-event-hub/{*}/{date:yyyy}/{date:MM}/{date:dd}/{date:HH}/{date:mm}/{*}
wasb:// is the scheme we'll use to access a storage account. The first part of the URI is in the format <container-name>@<storage-account>. The rest of the segments follow the structure we saw when browsing the storage account with Storage Explorer. We've created a date virtual column so we can filter these files by date/time and U-SQL can be smart about which files to read.
Then we new up an AvroExtractor and give it the schema. This schema can be found by examining one of the files we're extracting, or by reading the Event Hubs Archive documentation here.
The rest is just a standard U-SQL EXTRACT statement. We're selecting the Body from each Event Hub message and the date virtual column we created in the path.
Deserializing the JSON message body
That's really all that we need to extract the Event Hubs messages. Often these messages are serialized in JSON. We can use a SELECT statement to convert each message body to JsonTuples.
@jsonLogs =
SELECT JsonFunctions.JsonTuple(Encoding.UTF8.GetString(Body), "..*") AS json
FROM @eventHubArchiveRecords
WHERE date >= new DateTime(2016, 12, 6) AND date < new DateTime(2016, 12, 7);
As we can see from the Avro schema and EXTRACT statement above, the Body is actually a byte array. We're using some standard .NET (Encoding.UTF8.GetString()) to convert it to a string and then convert it to JsonTuples using a utility function.
Note the WHERE clause on the date virtual column. U-SQL will use it to narrow the set of files to extract.
Outputting to a CSV
Now that we have a bunch of JsonTuples, we can select a few properties from the JSON and OUTPUT them to a CSV file.
@logs =
SELECT json["remote"] AS remote,
json["code"] AS status_code,
json["agent"] AS user_agent
FROM @jsonLogs;
OUTPUT @logs
TO "/anthony/output/nginx-logs.csv"
USING Outputters.Csv();
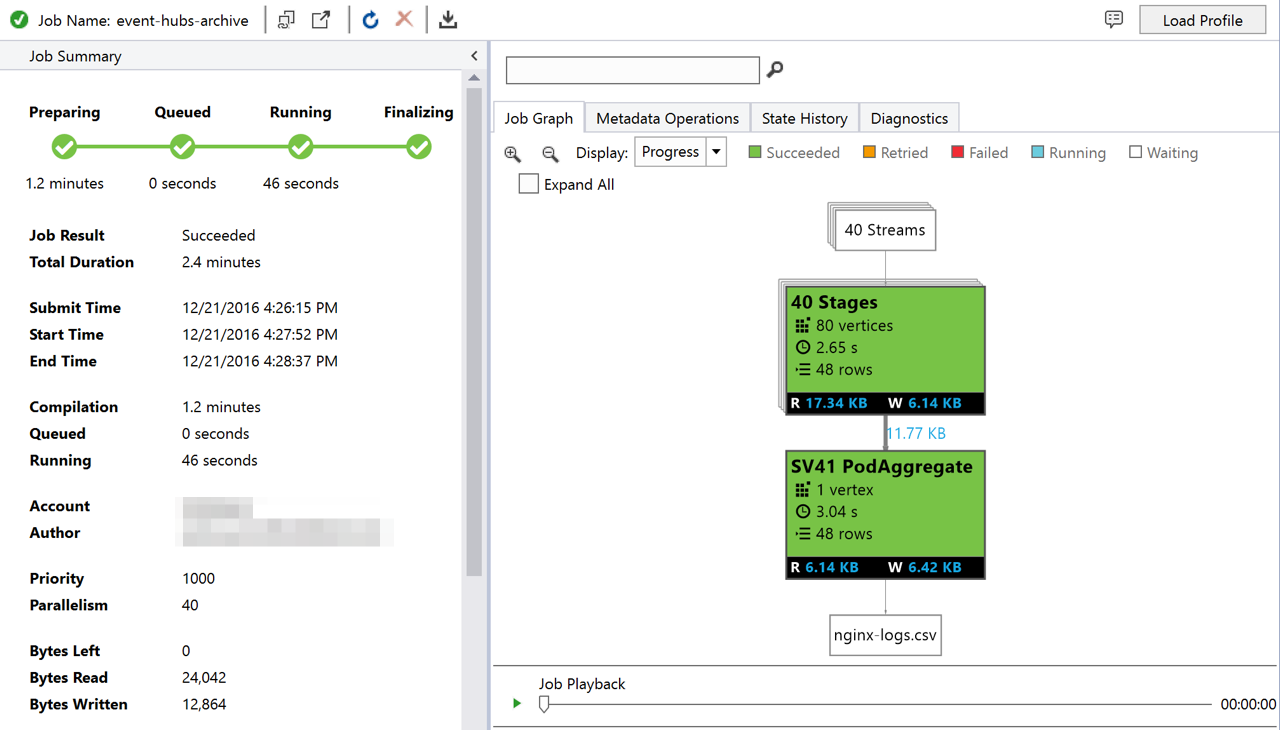
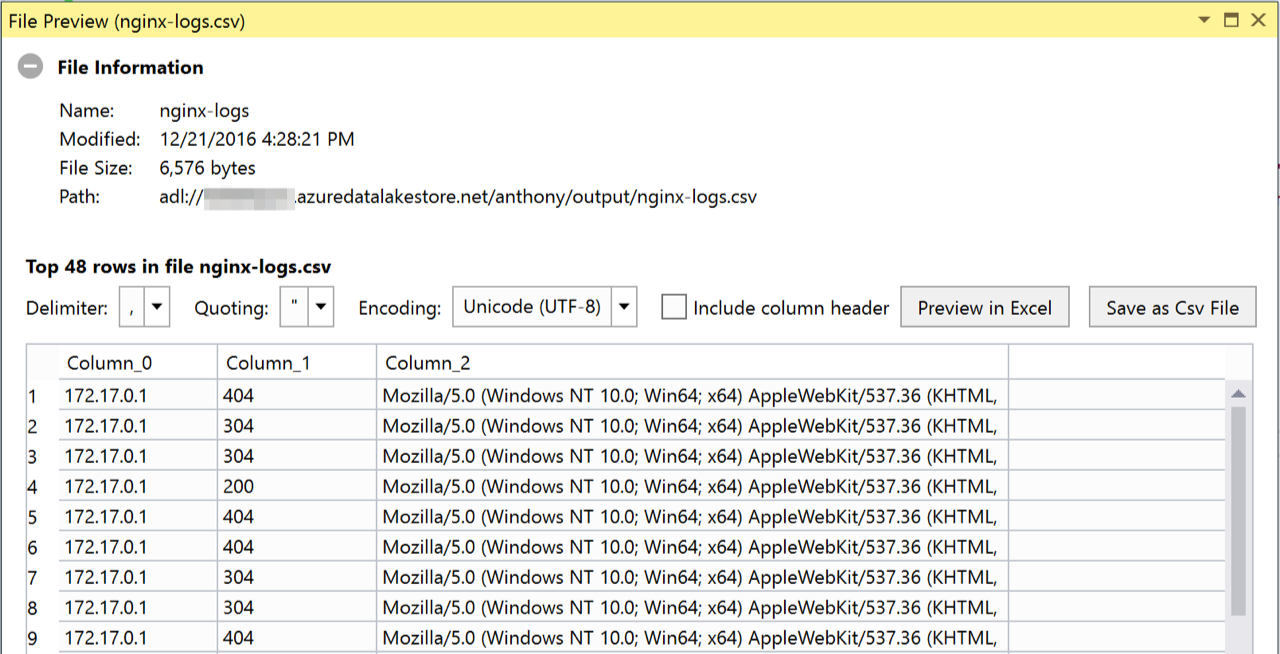
All we have to do now is run the U-SQL job against the remote Data Lake Analytics database and we'll get our results in a CSV file.
Azure Event Hubs Archive is a feature that allows the automatic archiving of Event Hubs messages into Blob Storage. A simple setting is all it takes to enable archiving for an Event Hub. It couldn't be easier.
Event Hubs Archive writes out the messages into files using Apache Avro serialization, which is a binary format with embedded schemas that is quickly becoming popular.
Azure Data Lake Analytics added an open source Avro extractor this week. In this article, we'll look at how to use Data Lake Analytics to query data stored by Event Hubs Archive.
Enabling Event Hubs Archive
The Archive feature can be turned on for any Standard Event Hub (it is not available on Basic because it needs its own consumer group). To enable it on an existing Event Hub, go to its properties. Turn on Archive, set the time and size windows (these dictate how granular the files are), and select a storage account and container to write the files to.
That's it, we're done. Of course, we can also do the same when creating a new Event Hub using the portal or an ARM template.
If there's data flowing through the Event Hub, check the storage account in a few minutes and we should see some files written there. One tool we can use to do this is Azure Storage Explorer.
Note the path... after the namespace and Event Hub name, the first number is the Event Hub partition id, followed by the year, month, day, hour, and minute. In the minute "folder", there are one or more files created for messages received during that timeframe. The format of the path will be important when we extract the data later.
Setting up Azure Data Lake Analytics
Data Lake Analytics is Azure's fully-managed, pay-per-use, big data processing service. It can extract data from Data Lake Store (of course), Blob Storage, and even SQL Database and SQL Data Warehouse.
We'll use its ability to extract data from Blob Storage to process the files created by Event Hubs Archive.
Adding a data source
Before we can extract data from Blob Storage, we have to set up a data source in Data Lake Analytics. One way to do this is via the portal.
In the Data Lake Analytics account, select Data Sources and click Add Data Source and fill out the required information.
Now the Data Lake Analytics account is set up to connect to the storage account.
Adding the Microsoft.Analytics.Samples.Formats assembly
Azure Data Lake Analytics provides out of the box extractors for TSV, CSV, and other delimited text files. It also allows us to bring our own extractors for other formats. The U-SQL team maintains a repository of extractors that we can add to our Data Lake Analytics accounts. They support JSON and XML; and starting this week, Avro is supported as well.
In order to use the open source extractors, we need to clone the repository and build the Microsoft.Analytics.Samples solution. Then we can use Visual Studio to add these assemblies to the Data Lake Analytics database:
Microsoft.Analytics.Samples.Formats.dllNewtonsoft.Json.dllMicrosoft.Hadoop.Avro.dll
The full instructions are here. It's simple to do and it only has to be done once per Data Lake Analytics database.
Extracting and processing Event Hubs Archive data
Now we're ready to get down to business and write some U-SQL. I like using Visual Studio for this. Using an existing Data Lake Analytics project or a new one, create a new U-SQL file.
In the first few lines, we'll reference the assemblies we deployed above and add some USING statements to simplify the code we're about to write.
REFERENCE ASSEMBLY [Newtonsoft.Json];
REFERENCE ASSEMBLY [Microsoft.Hadoop.Avro];
REFERENCE ASSEMBLY [Microsoft.Analytics.Samples.Formats];
USING Microsoft.Analytics.Samples.Formats.Avro;
USING Microsoft.Analytics.Samples.Formats.Json;
USING System.Text;
Extracting Avro
Next, we'll use the AvroExtractor to extract the data.
@eventHubArchiveRecords =
EXTRACT Body byte[],
date DateTime
FROM @"wasb://mycontainername@mystorageaccount.blob.core.windows.net/my-namespace/my-event-hub/{*}/{date:yyyy}/{date:MM}/{date:dd}/{date:HH}/{date:mm}/{*}"
USING new AvroExtractor(@"
{
""type"":""record"",
""name"":""EventData"",
""namespace"":""Microsoft.ServiceBus.Messaging"",
""fields"":[
{""name"":""SequenceNumber"",""type"":""long""},
{""name"":""Offset"",""type"":""string""},
{""name"":""EnqueuedTimeUtc"",""type"":""string""},
{""name"":""SystemProperties"",""type"":{""type"":""map"",""values"":[""long"",""double"",""string"",""bytes""]}},
{""name"":""Properties"",""type"":{""type"":""map"",""values"":[""long"",""double"",""string"",""bytes""]}},
{""name"":""Body"",""type"":[""null"",""bytes""]}
]
}
");
There's quite a bit to unpack here. Let's start with the URI.
wasb://mycontainername@mystorageaccount.blob.core.windows.net/my-namespace/my-event-hub/{*}/{date:yyyy}/{date:MM}/{date:dd}/{date:HH}/{date:mm}/{*}
wasb:// is the scheme we'll use to access a storage account. The first part of the URI is in the format <container-name>@<storage-account>. The rest of the segments follow the structure we saw when browsing the storage account with Storage Explorer. We've created a date virtual column so we can filter these files by date/time and U-SQL can be smart about which files to read.
Then we new up an AvroExtractor and give it the schema. This schema can be found by examining one of the files we're extracting, or by reading the Event Hubs Archive documentation here.
The rest is just a standard U-SQL EXTRACT statement. We're selecting the Body from each Event Hub message and the date virtual column we created in the path.
Deserializing the JSON message body
That's really all that we need to extract the Event Hubs messages. Often these messages are serialized in JSON. We can use a SELECT statement to convert each message body to JsonTuples.
@jsonLogs =
SELECT JsonFunctions.JsonTuple(Encoding.UTF8.GetString(Body), "..*") AS json
FROM @eventHubArchiveRecords
WHERE date >= new DateTime(2016, 12, 6) AND date < new DateTime(2016, 12, 7);
As we can see from the Avro schema and EXTRACT statement above, the Body is actually a byte array. We're using some standard .NET (Encoding.UTF8.GetString()) to convert it to a string and then convert it to JsonTuples using a utility function.
Note the WHERE clause on the date virtual column. U-SQL will use it to narrow the set of files to extract.
Outputting to a CSV
Now that we have a bunch of JsonTuples, we can select a few properties from the JSON and OUTPUT them to a CSV file.
@logs =
SELECT json["remote"] AS remote,
json["code"] AS status_code,
json["agent"] AS user_agent
FROM @jsonLogs;
OUTPUT @logs
TO "/anthony/output/nginx-logs.csv"
USING Outputters.Csv();
All we have to do now is run the U-SQL job against the remote Data Lake Analytics database and we'll get our results in a CSV file.